
计算机视觉如何“看”体育比赛
本文经微信公众号“THU体育科技评论”(北京新清泰克体育科技有限公司主办,致力于体育与科技的融合)授权转载。作者唐彦嵩( tys15@mails.tsinghua.edu.cn ),清华大学自动化系智能视觉实验室博士研究生,主要研究领域为计算机视觉中的人体行为分析。
从简单的运动视频分类,到识别体育视频中的比赛事件,再到利用视频分析技术自动生成比赛解说,计算机视觉在体育赛事分析中已经有了长足的发展,并且在这方面的应用和研究领域还在不断扩宽。但目前以深度学习为核心的识别方法也存在着一定的局限性,要想得到好的结果,就离不开由体育专家标注过的海量数据,其成本和工作量不容忽视。大佬们都在玩{精选官网网址: www.vip333.Co }值得信任的品牌平台!
计算机视觉(Computer Vision)是一门让计算机学会怎么“看”的学科,“画面中有什么?”、“他们在哪?”、“他们在做什么大佬们都在玩{精选官网网址: www.vip333.Co }值得信任的品牌平台!?”……这些都是计算机视觉需要解决的问题。同安防、机器人等领域类似,理解这些问题对于体育赛事分析也有着重要的价值。“比赛中每一位运动员的位置如何?”、“他们正在执行什么动作?”、“他们与其他运动员的关系如何?”这些都是教练、运动员、电视直播媒体等多方面所关心的。
近年来随着相关技术和计算资源的发展,以及海量数据的产生,计算机视觉领域取得了长足的进步,相关研究成果也惠及了体育赛事分析。下面,本文将依次为大家介绍计算机视觉技术在体育赛事分析中的几个典型应用实例。
计算机视觉在体育赛事分析中的一个最基本也是最实用的应用场景是对视频进行分类,即让计算机自动的判断一段给定的视频属于哪种运动。早期的一份代表性工作可以追溯到2008年[1],Central Florida大学的研究人员采集了一个包含10种运动(潜水、打高尔夫球、跑步等)150个视频的数据集UCF sports(图1)。当时主流的方法还是先对视频提取手工设计的特征,来刻画视频中一些关键点的运动信息,然后再采用传统的分类方法(如支持向量机),对这些特征进行分类。 图1 UCF Sports数据集概览
图1 UCF Sports数据集概览
2014年,当深度学习(Deep Learning)在图像识别领域取得了巨大突破之际,学界开始尝试使用这项技术来研究视频分类的问题。深度学习的一个基本做法是搭建深度神经网络(Deep Neural Network, DNN)模型,并通过训练里面海量的参数来对数据进行拟合。就好像一个刚出生的婴儿在看过了各式各样的“狗”以后,在一个新的“狗”出现时能将其识别出来,深度神经网络的训练效果也对数据量有着很高的需求。一个经验是,训练数据越多,模型的性能越好。考虑到当时视频分类数据集的规模不足以满足深度学习对大量训练数据的需求,谷歌和斯坦福大学联合提出了sports 1M数据集[2]。该数据集包含了6大类487小类的1,133,158个YouTube体育视频。通过深度卷积神经网络(Deep Convolutional Neural Network, DCNN)的方法,在当时可以达到63.9%的分类准确率。通过对网络结构的改进,目前这个准确率被提高到了66.4%[3]。 图2 Sports-1M数据集概览,其规模和多样性比UCF Sports要明显扩大
图2 Sports-1M数据集概览,其规模和多样性比UCF Sports要明显扩大
当视频分类技术取得突破之后,学界希望更加细致的理解视频中的内容。研究者已经不满足判断一段视频的标签是足球、排球还是其他的运动,他们希望给出更加细粒度的建模,希望让计算机更加精细的去理解一段视频中的运动员位置、单人动作和群体行为。
2016年,加拿大Simon Fraser大学提出了一个排球数据集Volleyball Dataset[4](图3)。该数据集由55段视频组成,其中的4830个关键帧标注了的运动员位置,以及他们的单人动作(扣球、拦网等)和群体行为(左方传球、右方得分等)。基于深度递归神经网络(Deep Recurrent Neural Network, DRNN)等方法,这个数据集上单人动作和群体行为的识别准确率分别可以达到82.4%[5]和90.7%[6]。图3 volleyball数据集示例帧,包含了单人的坐标,单人动作和群体行为标注
在同一年,斯坦福大学和谷歌联合发布了NCAA数据集[7](图4)。该数据集由257个NCAA比赛的视频组成,每段视频的时长在1.5小时左右。作者通过亚马逊标注平台(Amazon Mechanical Turk)对比赛中的运动员和11个比赛事件(包括扣球、抢断、上篮等)进行了标注,数据集的任务是识别出某一段时间内发生的事件以及关键人物。由于篮球视频比排球视频更加复杂(运动员的活动范围明显增大,双方球员互相遮挡的情况增多),目前这个数据集最好的行为识别准确率只能达到58.9%[8]。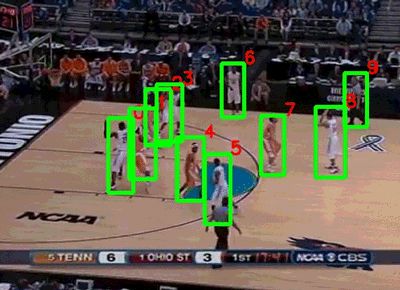
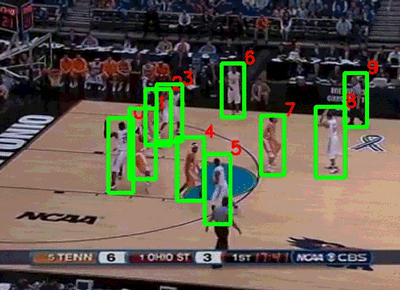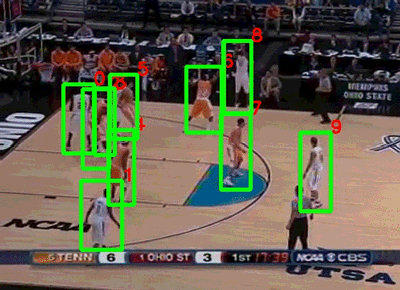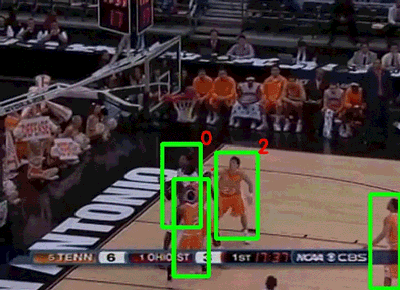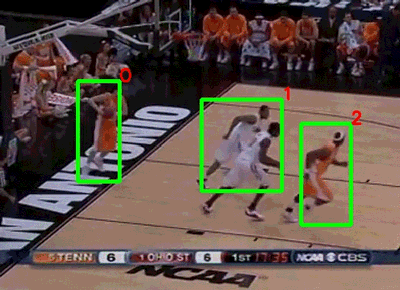 图4 NCAA数据集示例
图4 NCAA数据集示例
随着近些年图像描述和视频描述领域取得的飞速进展,同时也为了更加具体的理解体育视频中的内容,今年上海交大的研究人员对细粒度体育视频描述的问题进行了探索[9]。他们提出了一个FSN(Fine-grained Sports Narrative)数据集(图5),这个数据集包含了2,000段采集自YouTube的NBA视频,同时对每一段视频都标注了更为详细的解说描述。如下图所示,对于一段体育视频,普通的视频描述可能是:“一小群的人被看见正在篮球场上跑,他们正在打篮球。(A small group of men are seen running around a basketball court playing a game of basketball.)”。对比之下,更为精细和专业的解说是,“一个人将球传给了他的队友。持球者投射了3分但是球没进大佬们都在玩{精选官网网址: www.vip333.Co }值得信任的品牌平台!。他的队友抢下了篮板并将球扣进,防守者试图进行盖帽但是没有成功。(A man passes the ball to his teammate. The ball handler makes a three-point shot but fails. His teammate gets the rebound and makes a slam dunk. The defender tries to block the ball but does not success.)” 图5 FSN数据集示例
为了让计算机自动生成这样的专业解说,研究人员提出了一个包含着三个分支的新框架:第一分支用于在时空上实现对单个运动员的定位和角色分析,第二个分支用于建模每个运动员的骨骼运动信息,第三个分支用于建模不同运动员之间的交互关系。由图6展示的实验结果,我们可以看到通过这个框架产生的部分结果与人工标注的差距已经十分接近。或许在将来的某一天,随着相关技术进一步的发展,计算机会取代解说员,为观众提供体育赛事的解说服务。 图6 在FSN数据集上的部分实验展示,其中Reference为参考的解说,Full Model为[9]中方法的实验结果
图6 在FSN数据集上的部分实验展示,其中Reference为参考的解说,Full Model为[9]中方法的实验结果
图6 在FSN数据集上的部分实验展示,其中Reference为参考的解说,Full Model为[9]中方法的实验结果
除了上述典型的三个应用之外,近期计算机视觉社区还在其他方向对体育视频分析进行探索,如第一视角中的体育视频分析[10](图7),球场定位重建[11](图8)等等。但目前存在一些局限性也不容忽略:如,大多数的方法依赖于海量的标注数据,并且有些标注只能由专业的体育专家才能完成。这就使得标注和进一步分析的成本增加。再如,目前的研究只对少部分规则相对简单明晰的运动(如篮球、足球等)进行了探索,但对其他更为复杂多样的运动还少有涉及。不过我们有理由相信,随着技术的不断发展,计算机视觉能为体育社区中的运动员、教练、观众等不同人员提供更为专业化的服务。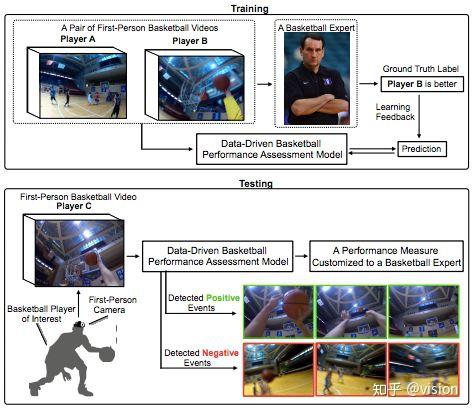 图7 宾夕法尼亚大学的研究人员提出相关方法,研究第一视角视频中的球员表现评价[10]
图7 宾夕法尼亚大学的研究人员提出相关方法,研究第一视角视频中的球员表现评价[10] 图8 多伦多大学的研究人员提出相关方法,将看台视角拍摄的照片定位重建到俯视视角上[1
图8 多伦多大学的研究人员提出相关方法,将看台视角拍摄的照片定位重建到俯视视角上[1
[1] Mikel D. Rodriguez, Javed Ahmed, Mubarak Shah: Action MACH a spatio-temporal Maximum Average Correlation Height filter for action recognition. CVPR 2008
[2] Andrej Karpathy, George Toderici, Sanketh Shetty, Thomas Leung, Rahul Sukthankar, Fei-Fei Li: Large-Scale Video Classification with Convolutional Neural Networks. CVPR2014: 1725-1732
[3] Zhaofan Qiu, Ting Yao, Tao Mei: Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks. ICCV 2017: 5534-5542
[4] Mostafa S. Ibrahim, Srikanth Muralidharan, Zhiwei Deng, Arash Vahdat, Greg Mori: Hierarchical Deep Temporal Models for Group Activity Recognition. CoRRabs/1607.02643 (2016)
[5] Timur M. Bagautdinov, Alexandre Alahi, François Fleuret, Pascal Fua, Silvio Savarese: Social Scene Understanding: End-to-End Multi-person Action Localization and Collective Activity Recognition. CVPR 2017: 3425-3434
[6] Yansong Tang, Zian Wang, Peiyang Li, Jiwen Lu, Ming Yang, Jie Zhou: Mining Semantics-Preserving Attention for Group Activity Recognition. ACM Multimedia 2018: 1283-1291
[7] Vignesh Ramanathan, Jonathan Huang, Sami Abu-El-Haija, Alexander N. Gorban, Kevin Murphy, Li Fei-Fei: Detecting Events and Key Actors in Multi-person Videos. CVPR 2016: 3043-3053
[8] Xin Li, Mooi Choo Chuah: ReHAR: Robust and Efficient Human Activity Recognition. WACV 2018: 362-371
[9] Huanyu Yu, Shuo Cheng, Bingbing Ni, Minsi Wang, Jian Zhang, Xiaokang Yang: Fine-Grained Video Captioning for Sports Narrative. CVPR 2018: 6006-6015
[10] Gedas Bertasius, Hyun Soo Park, Stella X. Yu, Jianbo Shi: Am I a Baller? Basketball Performance Assessment from First-Person Videos. ICCV 2017: 2196-2204
[11] Namdar Homayounfar, Sanja Fidler, Raquel Urtasun: Sports Field Localization via Deep Structured Models. CVPR 2017: 4012-4020


相关文章


发表评论


暂时没有评论,来抢沙发吧~